2022. 4. 14. 12:10ㆍ전공공부/전자전기전공
본 글에서는 오디오 신호처리의 전체적인 overview를 소개합니다.
자세한 내용은 다른 블로그나 논문을 참고해주시면 되겠습니다.
1. FFT
FFT는 Fast Fourier Transform으로 divide and conquer algorithm을 활용해, 라이브러리에서 FT 이용시 FFT를 사용.
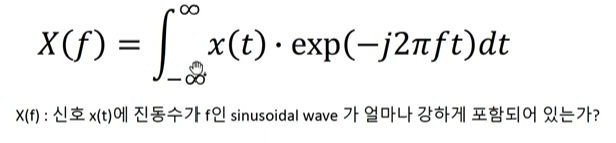
FT의 의미는 x(t)와 phasor가 얼마나 유사한지 나타내줍니다.
그래서 시간에 대한 wave amplitude값을 사인파로 분해합니다.
즉 타임 도메인에서 주파수 도메인으로 매핑시켜주는 역할을 합니다.
하지만 FFT의 가장 큰 문제점은 시간도메인의 정보를 완전히 잃어버린다는 것입니다.
2. STFT - Spectrogram
그 문제를 해결하기 위해 STFT가 등장했습니다.
STFT는 Short-Time Fourier Transform으로 time window를 움직이며 FFT를 수행시켜 local time area 진동수 성분을 파악합니다.

다음과 같이 각각 윈도우마다 FFT를 진행합니다.
여기서 윈도우가 overlap되는 것을 볼 수 있습니다. 이는 frame간 정보가 자연스럽게 이어지게 하기 위해서 입니다.
자세한 내용은 여기서 찾아보실 수 있습니다.
https://sanghyu.tistory.com/38
음성신호처리에서 frame 생성시 overlap을 하는 이유
동아리에서 논문세미나를 하다가 speech를 전공하지 않으시는 분들에게 왜 frame을 overlap하냐는 물음을 받았다. 음성신호를 연구하는 사람들이라면 overlap을 당연하게 받아들이겠지만, 어떻게 말로
sanghyu.tistory.com
그래서 각각의 시간 frame마다 푸리에 주파수 값이 나타나게 됩니다. 이를 그림으로 표현하면 다음과 같습니다.
x축이 주파수, y축이 시간(frame)입니다. 원래는 축이 반대인데 편의를 위해 돌렸습니다.

이 spectrogram을 활용해서 audio(sound) classification이나 sound event detection등에서 input으로 활용이 됩니다.
문제는 이 scale이 필요없는 고주파 부분까지 포함하게 됩니다.
인간의 귀는 저주파에 민감하고, 고주파에 둔감한데 이를 수식으로 표현하면 mel-scale이 됩니다.
그래서 보통 mel-scale spectrogram을 사용합니다.
하지만 이것도 문제가 있는게 윈도우 사이즈를 정해야 한다는 것입니다.
Heisenberg's Uncertainty principle of Fourier Transform
- 윈도우가 작다면 → 개수 늘어남 : 주파수영역 해상도 떨어짐
- 윈도우가 크다면 → 개수 적어짐: time 영역 해상도 떨어짐
—> 높은 주파수는 윈도우 크기를 작게, 낮은 진동수는 크기를 넓게 해야 합니다.
3. Wavelet transform : scalogram
기존 FFT는 sinusoidal x(t)로 분해했는데, WT는 엔지니어가 임의로 선택한 파동으로 분해가 가능합니다.
그래서 더 적합한 spectrogram을 사용할 수 있습니다. 따라서 주파수, 시간 영역 모두 높은 해상도를 갖게 됩니다.
자세한 건 밑의 링크를 참고해 주세요
Audio Classification using Wavelet Transform and Deep Learning
A step-by-step implementation to classify audio signals using continuous wavelet transform (CWT) as features.
medium.com
오디오 classification이나 sound event detection 논문을 찾아보았을 때 안타깝게도 scalogram은 제대로 활용되지 않았습니다. 그 이유는 저도 잘 모르겠네요. 나중에 알게 된다면 내용을 추가하도록 하겠습니다.
4. 기본적인 용어 참고
- amplitude: loudness
- sample rate : 22000Hz라면 1초당 22000 샘플 → 1/22000초마다 계산 (x축)
- bit depth : quality of sound (== pixel of image) (y축)
- mono :하나, streo : 2개의 mono
- chunk: 프레임 내 바이트 수
- sample_rate * second : 총 프레임 수
- depth = sample_rate * second / chunk = 총 바이트 수
- little endian vs big endian
- wav = header(44) + depth x chunk x 2byte(int16) x channel #
5. 사용하는 라이브러리
주로 파이썬을 사용하는데 pyaudio, librosa를 사용합니다.
'전공공부 > 전자전기전공' 카테고리의 다른 글
| <딥러닝, 머신러닝> classify할 대상을 다양하게 train/test set에 넣고 싶다면? (0) | 2021.10.29 |
|---|---|
| tf.keras.layers.Dense의 Args 분석 - TNT 스터디 중 몰랐던 것 (0) | 2021.09.17 |
| ConcatOp: Dimensions of inputs should match shape ... error가 나올 때 (0) | 2021.09.17 |
| TNT 스터디 2주차 몰랐던 것(1) (0) | 2021.09.17 |
| VScode, Colab에서 명령어가 입력 되지 않을 때 한가지 방법 (0) | 2021.09.16 |